
Panopto sucks, but it doesn’t have to.
Update May 2026:
Teddy has been selected to be featured on the UW Student Innovation Lab Community Showcase!
Update February 2026:
I had a meeting where I pitched Teddy to the CTO of Panopto and two UW representatives :)
Are lectures stressing you out? Can’t find the exact moment a professor said something or want to check if they gave any hints about an upcoming exam? Teddy is here to give you a big warm hug. Just .

Teddy is available on any Panopto video with captions (UW only for now). Just install the chrome extension, navigate to a Panopto video, and hit . No sign up required, no ads, no wasted time. You might wait about five seconds for Teddy to process captions that aren’t in the database, but all subsequent visits have no load time. That includes you and any other Teddy users that click on that video.
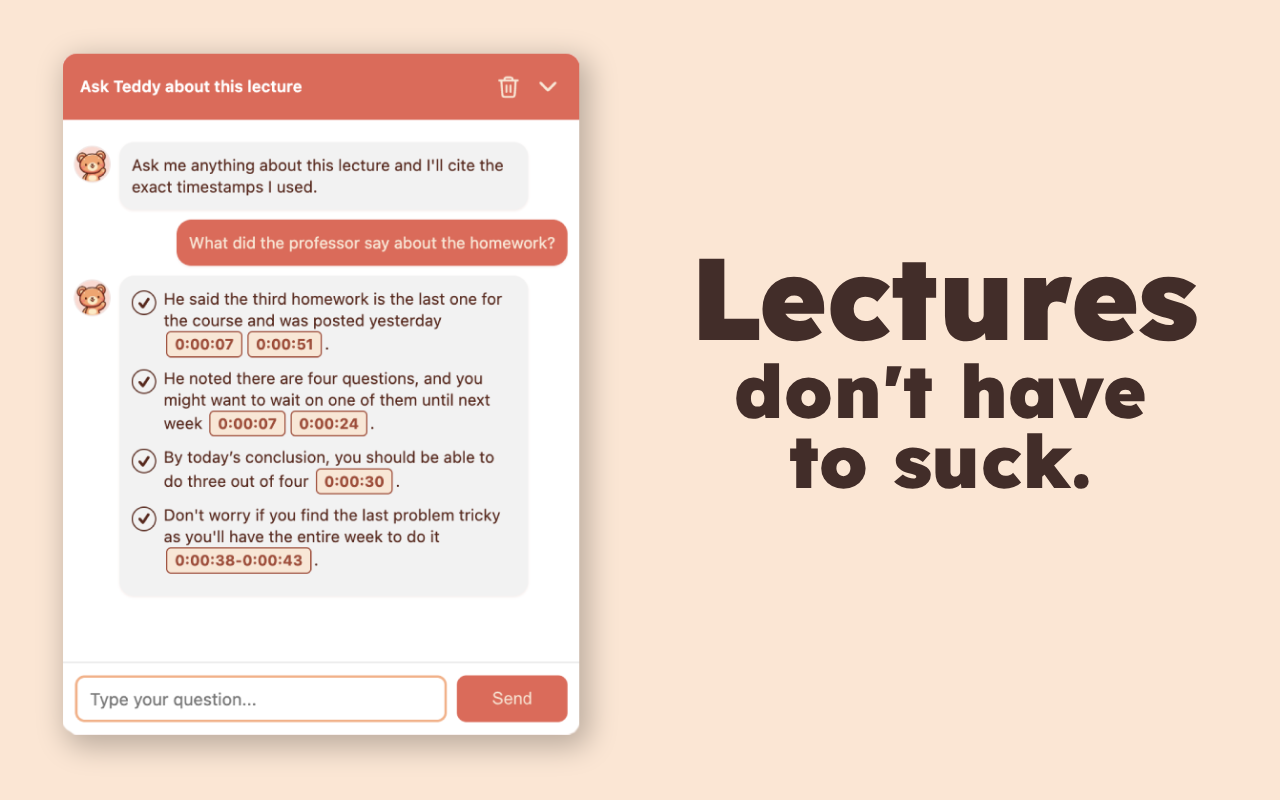
Psst! Try the demo on this page.
Instead of using content from Panopto videos, this demo indexes all of sacrosaunt.com, using the same pipeline as the Teddy extension. Just hit .
Teddy was a fork of a project I completed in September called DirtyRag. The DirtyRag project was aimed at solving one of the biggest issues plaguing me on one of my favorite sites, Doctor of Credit (DoC), a blog focused on credit cards and banking deals. Information on that site was scattered and the search feature was subpar (keyword search only). There was a trove of information, tens of thousands of blog posts, and over a million comments.
Because everyone’s personal finance situation is different, finding information that actually applied to you was slow. Tracking down the right credit cards and deals for your case was a very manual process. Even when you did find something useful, iterating on that knowledge was difficult.
Introducing DirtyRag, a containerized, end-to-end Flask (Python) app that injected a JavaScript chat interface into any unauthenticated Wordpress site, scraped the site on a schedule, stored chunked and embedded content in Postgres for Retrieval Augmented Generation (RAG), handled rewritten queries and reranking, ran inference with OpenAI, and returned answers with clickable citations to the exact posts or comments used. A chat interface was a logical implementation for a client interface because, at worst, it worked like a traditional keyword search feature by returning exact results with links, and at best allowed for semantic retrieval and a rich conversation building on previous messages, arriving at a result that was tailored exactly to your use case.
The DirtyRag proof-of-concept was built with maximum cost optimizations in mind, relying on a single VPS to run the application and database containers (Docker). It initially used gpt-5-nano for inference and rewriting on the lowest verbosity and reasoning settings. I found the latency to be unnaceptable and switched providers to Anthropic when creating Teddy. The latency with claude-haiku-4.5 was about the same (albeit with slightly better quality), so I switched to OpenRouter to try out some lightweight models. Right now, Teddy is running gemini-2.5-flash-lite for query rewriting and inference, balancing quality with some of the lowest inference latency that I’ve seen. For embedding, I used Voyage AI’s voyage-3.5-lite and rerank-2.5-lite for reranking. Voyage AI has an incredibly generous free tier that allowed me to develop without worrying about quotas. At the time of writing, I have the vast majority of my free embedding tokens remaining.
This pipeline allows for the highest quality of retrieval results as well as strong inference results. Its sequential nature limited latency optimization because each step depended on the previous one: input query rewriting → embedding → DB retrieval → reranking → injection into context and inference → returning result to frontend. The response times of external services are highly variable, ranging from low hundreds of milliseconds to over a second. Luckily, reusing connection pipelines and the OpenAI’s caching can reduce the response latency by up to 80 percent for subsequent requests.
When tracking down slow DB results, I discovered that indexes were not being hit and that I didn’t implement pgvector properly. Once those issues were addressed, query times dropped by over 97 percent to more normal values.
Finally, I implemented some visual tricks as well. Studies show that typing indicators reduce perceived wait times between responses and reduce frustration. In my personal experience, this change made the interface feel more engaging and enjoyable.
I had an epiphany and realized that my application foundation was pretty versatile. A chat interface can be applied on almost any website, and data can be ingested in many different ways. For example, DirtyRag relied on the WordPress API to retrieve site content, and Teddy extracted video captions. Teddy’s ingestion pipeline is simpler, with no periodic rescraping (captions don’t change), more consistent text (no server-side Beautiful Soup parsing), and much less total data. This also allows for a simpler database setup: simpler inter-table relationships, simpler indexes (IVFFLAT is no longer worth it), and no need for query warmers.
In DirtyRag, managing CPU and RAM usage on a VPS running all my logic was tricky. Although I did vertically scale at some point, vertical scaling is not sustainable or viable long term. For Teddy, I used my go-to hosting solution, Fly.io. Optimizing for cost again, I settled for an unmanaged Postgres solution, using a separate application container dedicated to the database and stateless application containers for the rest. This let me scale my app horizontally with ease if I ever needed to, long before database overload becomes a realistic concern.
Obviously, having a single copy of my database can be problematic for a couple reasons. If your app had users from all around the world, you’d want replicas near them for better latency. You’d also want to have replicas for redundancy in case of critical data loss. Considering that my users are all in the same region, the first argument doesn’t apply. Also, if my database container experiences a critical failure and lost all data, the most important thing lost would be my metrics. Captions can always be re-chunked and re-embedded at the cost of a single user waiting five seconds before using Teddy. Conversation history isn’t stored on the server and instead is cached locally in the browser for convenience. Given all that, a single database container makes sense at this stage. Besides, Fly.io does automatic volume snapshots, so I can restore my database if I really need to. My precious metrics!
Since the information being processed in Teddy is different from DirtyRag, the processing pipeline had to be heavily adjusted. The Teddy extension extracts Panopto video captions and timestamps, and forwards them to the backend along with some video identifiers. Captions are cleaned and stored raw. They’re then chunked into 400 token segments – combining multiple adjacent captions, retaining enough context for better semantic retrieval. After retrieval, reranking, and selecting the top k chunks, the backend fetches the original timestamp split captions to pass to an LLM. This allows the model to provide much more precise citations, because a single chunk may span multiple minutes on its own.
I woke up one morning and realized there weren’t enough chatbots out there. I made another, so now there’s enough.
In all seriousness, the main motivation behind DirtyRag was to scratch an itch: I wanted to implement a RAG. A chat interface made sense for complex, context-building queries, and a RAG made sense because DoC is a site where trust and citations matter. One thing that the DoC owners pride themselves on is trustworthiness. They don’t use affiliate links, always provide sources, and interact heavily with their community. Building DirtyRag with trust as its foundation made RAG a logical choice because it provides deterministic citations while using a nondeterministic model.
As stated in other docs, my projects usually start with trying to fix a problem I’m experiencing. In this case, it was the scattered information on Doctor of Credit, and I’m sure I wasn’t the only one feeling that pain.
As for Teddy, I was unhappy with the Panopto interface. The search feature is mediocre at best and lectures can be incredibly lengthy, so manually seeking through the video isn’t always an option. A chat interface improves engagement and lets students “talk” to their lectures, ask follow-up questions, and get answers tied directly to the content. Since I already had a strong foundation, the implementation was fast. Adapting DirtyRag was straightforward.
My biggest concern is abuse of the system. I do implement rate limiting, but not IP based rate limiting. IP rate limiting doesn’t make sense when most of a services users are college students because hundreds of students might share a single IP address. Blocking an IP over one user’s abuse could lock out many others. I don’t currently implement a sign-up flow because it introduces too much friction, and isn’t necessary yet, but I’d consider it if abuse becomes a problem.
I attempted to monetize DirtyRag (NOT Teddy) through a licensing or one-time purchase agreement with Doctor of Credit, but they weren’t interested. I should’ve anticipated that before approaching a site owner known for his frugality 😆. I also approached the University of Washington requesting access to their SSO-authenticated WordPress endpoint to explore a potential (unmonetized) integration with UW’s site pages, but the Marketing and Communications department wasn’t interested in exposing their endpoint.
As for Teddy, my largest expenses are server and inference costs. Monetization is tricky apparently. Ads would destroy the experience and brand. Requiring a subscription would add friction and shrink the userbase. A one-time payment model doesn’t work because inference costs never stop. Besides, college students are broke.
So, does Teddy live up to its standards, ideologies, goals, and motivations?
This project was incredible. Teddy was by far my largest and most complete project, given how many components were involved. So many APIs, so many moving parts, and an overwhelming number of design decisions. This project pushed me across the board, from system design to technical skill, to collaborating on everything from core architecture decisions to marketing, brand identity, and promotional strategy. DirtyRag was so fun to work on that I basically did a weeklong marathon to implement it from start to finish. Once the idea for Teddy came to mind, I launched into another multi-week sprint.
Even before fully launching, I suspected Teddy would be a success, at least in my mind. The first person I showed the prototype to said, “Oh what? That’s sick! I would totally use that.” That’s when I knew I was onto something.